STREAM
This section contains all information related to the STREAM benchmark.
Contents:
Configuration Parameters
In Table 2 the configuration parameters are shown that are used to modify the kernel. All other parameters can also later be changed with the host code during runtime.
Parameter |
Description |
|---|---|
|
Replicates all kernels the given number of times. This allows to simultaneously schedule multiple kernels with different input data. The data set might be split between the available kernels to speed up execution. |
|
Size of the local memory buffer that stores intermediate values read from global memory. Used to reduce the impact of memory latency on the execution time. |
|
Data type used for host and device code. |
|
If |
|
Loop unrolling factor for the inner loops in the device code. Similar effect to |
Detailed Description
The goal of the STREAM benchmark is to measure the sustainable memory bandwidth in GB/s of a device using four different vector operations: Copy, Scale, Add and Triad. All kernels are taken from the STREAM benchmark v5.10 and thus slightly differ from the kernels proposed in [LUS05]. The benchmark will sequentially execute the operations given in Table 3 . PCI Read and PCI Write are no OpenCL kernels but represent the read and write of the arrays to the device memory. The benchmark will output the maximum, average, and minimum times measured for all of these operations. For the calculation of the memory bandwidth, the minimum times will be used.
PCI Write |
write arrays to device |
Copy |
\(C[i] = A[i]\) |
Scale |
\(B[i] = j \cdot C[i]\) |
Add |
\(C[i] = A[i] + B[i]\) |
Triad |
\(A[i] = j \cdot C[i] + B[i]\) |
PCI Read |
read arrays from device |
The arrays A, B, and C are initialized with a constant value over the whole array. This allows us to validate the result by only recalculating the operations with scalar values. The error is calculated for every value in the arrays and must be below the machine epsilon \(\epsilon < ||d - d'||\) to pass the validation.
A flow chart of the calculation kernel that can perform all four STREAM operations is given in Fig. 3 .
Since on FPGA the source code is translated to spatial structures that take up resources on the device, a single combined kernel allows for best reuse of those resources.
The computation is split into blocks of a fixed length, which makes it necessary that the arrays have the length of a multiple of the block size.
In a first loop, the input values of the first input array Input1 are loaded into a buffer located in the local memory of the FPGA.
The size of this local memory buffer can be specified with the DEVICE_BUFFER_SIZE parameter.
While the values from the first input array are loaded, they are multiplied with a scaling factor scalar.
This allows the execution of the Copy and Scale operation.
In the case of Copy, the scaling factor is set to 1.0.
In the second loop, the second input Input2 is only added to the buffer, if a boolean flag is set.
Together with the first loop, this makes it possible to recreate the behavior of the Add and Triad operation.
In the third loop, the content of the buffer is stored in the output array Output located in global memory.
Note, that depending on the STREAM operation, different arrays are used as input and output array with the same kernel.
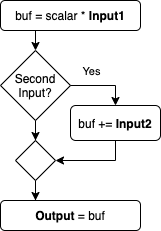
Fig. 3 Flow chart of the STREAM calculation kernel that can execute all four STREAM operations. Global memory accesses are written in bold. buf is the local memory buffer and scalar a constant kernel parameter. The second input can be selected over a boolean flag, which is also a kernel parameter.
DATA_TYPE and VECTOR_COUNT can be used to define the data type used within the kernel.
If VECTOR_COUNT is greater than 1, OpenCL vector types of the given length are used.
Depending on the used data type, the loops can be unrolled with the GLOBAL_MEM_UNROLL parameter to achieve the optimal size for the memory interface.
Since some of the STREAM operations show an asymmetry between reads and writes from global memory, the best performance can be achieved if a single bank is used for all three arrays.
DDR memory bandwidth is not bidirectional, so with a sufficient memory interface width, each of the three phases can fully utilize all available bandwidth of the global memory bank.
Intermediate results are stored in a local memory buffer that can be modified in size over a configuration parameter.
This makes STREAM bandwidth bound by the global memory and also slightly resource bound by the BRAM.
The kernel has to be replicated to fully utilize all available memory banks and at the same time the local memory buffer size has to be increased to achieve larger burst sizes and decrease the impact of memory latency.
Configuration Hints
For the best performance result, the kernel should be replicated for every memory bank. In a next step, the size of the local memory buffer should be increased as large as possible to achieve larger global memory burst sizes. If the kernel frequency drops below the frequency of the memory interface, it might be beneficial to reduce the buffer size slightly to achieve at least the memory interface frequency.
LUSZCZEK, Piotr, et al. Introduction to the HPC challenge benchmark suite. Ernest Orlando Lawrence Berkeley NationalLaboratory, Berkeley, CA (US), 2005.
