PTRANS
This benchmark calculates a distributed blocked matrix transposition with \(C = B + A^T\) where \(A,B,C \in \Bbb R^{n \times n}\). So, a matrix \(A\) is transposed and added to another matrix \(B\). The result is stored in a separate buffer. All matrices are divided into blocks and the blocks are distributed over multiple FPGAs, so the FPGA will need to complete the calculation using an inter-FPGA network.
The benchmark is designed to be easily extendable with different distribution schemes on the host side.
Configuration Parameters
In Table 10 the configuration parameters are shown that are used to modify the kernel. All other parameters can also later be changed with the host code during runtime.
Parameter |
Description |
|---|---|
|
Replicates all kernels the given number of times. This allows to create a kernel pair for every available external channel in case of the circuit-switched network. |
|
Size of the matrix blocks that are buffered in local memory and also distributed between the FPGAs. |
|
Width of the channels in data items. Together with the used data type, the width of the channel in bytes can be calculated. |
|
Specifies the used data type for the calculation. |
Detailed Description
As mentioned at the beginning, the host code of this benchmark is designed to support different data distribution schemes between the FPGAs.
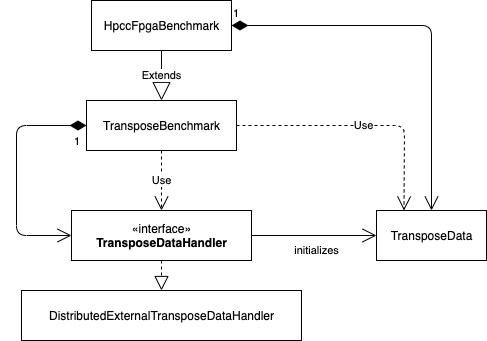
Fig. 6 Class diagram showing the integration of the TransposeDataHandler interface into the implementation of the host code
An overview of the structure of the host code is given in Fig. 6.
Different host processes are communicating using MPI to allow scaling over multiple FPGAs, that may be installed on different nodes in a compute cluster.
Every MPI rank is in charge of a single FPGA and all objects shown in the figure are created on every MPI rank.
This means, the data handler and the generated data may differ between the MPI ranks depending on the chosen distribution scheme.
Therefore, the implementation introduces a new interface: TransposeDataHandler.
Implementations of this interface are managing the initialization of the TransposeData object for a given MPI rank,
which again holds the allocated memory for the kernel execution on the FPGA.
The default data distribution scheme is the block scattered distribution or also called PQ distribution.
The data exchange via MPI used in the baseline implementation is based on the algoorithm given in [CHO95]. The matrix transposition of the base implementation is implemented in a single kernel executing the following pipelines sequentially for every matrix block:
Read a block of matrix A into local memory
Read block of matrix A transposed from local memory, read block of matix B from global memory, add both blocks and store result in second local memory buffer
Write the second memory buffer back to global memory.
With this approach, every pipeline will either read or write to global memory. With that, the transpose kernels can be replicated per memory bank and utilization of the global memory bandwidth is maximized.
Choi, Jaeyoung, Jack J. Dongarra, and David W. Walker. “Parallel matrix transpose algorithms on distributed memory concurrent computers.” Parallel Computing 21.9 (1995): 1387-1405.
