FFT
This section contains all information related to the FFT benchmark. The benchmark executes a batched calculation of 1d FFTs on a single FPGA. It is possible to specify the size of the FFT and the number of kernel replications.
Contents:
Configuration Parameters
In Table 7 the configuration parameters are shown that are used to modify the kernel. All other parameters can also later be changed with the host code during runtime.
Parameter |
Description |
|---|---|
|
Replicates all kernels the given number of times. This allows to simultaneously schedule multiple kernels with different input data. The data set might be split between the available kernels to speed up execution. |
|
Size of the FFTs will be \(2^{LOG\_FFT\_SIZE}\) and can not be changed during runtime! Larger FFT sizes will utilize more FPGA resources and a deeper pipeline. |
Detailed Description
In the FFT benchmark calculates a batch of 1d FFTs of a predefined size which can be specified using the LOG_FFT_SIZE parameter.
The benchmark consists of up to three different kernels that are connected over channels (or pipes for Xilinx) to stream the data from
one kernel to the other.
Fig. 4 shows the data flow through these three kernels.
For Intel devices, the store kernel is not needed and instead the fft1d kernel is directly writing to global memory.
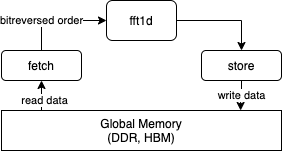
Fig. 4 The data movement through the three kernel. The separation of the data accesses into multiple kernels allows an easier implementation of all routines in a single pipeline and the use of memory bursts to speed up global memory accesses.
- fetch:
This kernel is a single pipeline that loads data from the global memory and puts the data in bitreversed order. Because of that it necessary to store the whole data for an FFT in local memory which also delays the forwarding of the data. The data is then forwarded to the fft1d kernel for the actual calculation.
- fft1d:
It is also a single pipeline that contains all stages of the FFT in an unrolled fashion. The data is passed to the different stages using a shift register. The data is then forwared to the store kernel or directly written to global memory.
- store:
The store kernel is only used on Xilinx devices. The kernel reads data from a pipe and writes it without modifications to global memory. Since no conditionals are needed it is possible for the compiler to infer global memory bursts.
It is allowed to create multiple replications of the benchmark kernels with the NUM_REPLICATIONS parameter and split the batch between the replications.
The benchmark kernels are based on a reference implementation for the Intel OpenCL FPGA SDK included in version 19.4.0 and slightly modified to also allow execution on Xilinx FPGAs.
A batch of FFTs is used to increase the overall execution time of the benchmark to decrease measurement errors.
Also, the kernel pipeline is better utilized when calculating multiple FFTs sequentially.
Data will get delayed in the fetch and fft1d kernel but batched execution allows to hide this latency.
The number of FLOP for this calculation is defined to be \(5*n*ld(n)\) for an FFT of dimension \(n\).
The result of the calculation is checked by calculating the residual \(\frac{||d - d'||}{\epsilon ld(n)}\) where \(\epsilon\) is the machine epsilon, \(d'\) the result from the reference implementation and \(n\) the FFT size.
Expected Bottlenecks
In general, the benchmark can be both memory bandwidth and compute-bound. The implementation in a single pipeline allows to continously read and write from global memory. Since reads and writes are symmetric and the memory bandwidth is uni-directional, we need two memory banks per replication. Besides that, the size of the FFT has an impact on the number of floating-point operations that are done per data item.
- FFT Size:
A larger FFT size will lead to more calculations per data item (\(5 * ld(n)\) single-precision floating-point operations for FFT size n). Also, the shift register size depends on the used FFT size, so BRAM and logic usage will increase for larger sizes.
- Kernel Replications:
Allows utilizing more memory banks. Since the benchmark is not solely memory-bound, it might be better for the overall benchmark performance to increase the FFT size instead of adding more kernel replications. The expected performance can be calculated using Eq.1.
where f is the minimum of the kernel frequency and the frequency of the memory interface.
